
I recently had a requirement to load a large amount of data into an application, as fast as possible.
The data in question was about 100,000 transactions, stored line-by-line in a file, that needed to be sent over HTTP to a web application, that would process it and load it into a database.
This is actually pretty easy in .NET, and super efficient using async/await:
| async static Task Main(string[] args) | |
| { | |
| var httpClient = new HttpClient(); | |
| httpClient.BaseAddress = new Uri("https://myserver"); | |
| using (var fileSource = new StreamReader(File.OpenRead(@"C:\Data\Sources\myfile.csv"))) | |
| { | |
| await StreamData(fileSource, httpClient, "/api/send"); | |
| } | |
| } | |
| private static async Task StreamData(StreamReader fileSource, HttpClient httpClient, string path) | |
| { | |
| string line; | |
| // Read from the file until it's empty | |
| while ((line = await fileSource.ReadLineAsync()) != null) | |
| { | |
| // Convert a line of data into JSON compatible with the API | |
| var jsonMsg = GetDataJson(line); | |
| // Send it to the server | |
| await httpClient.PostAsync(path, new StringContent(jsonMsg, Encoding.UTF8, "application/json")); | |
| } | |
| } |
Run that through, and I get a time of 133 seconds; this isn’t too bad right? Around 750 records per second.
But I feel like I can definitely make this better. For one thing, my environment doesn’t look exactly look like the diagram above. It’s a scaled production environment, so looks more like this:
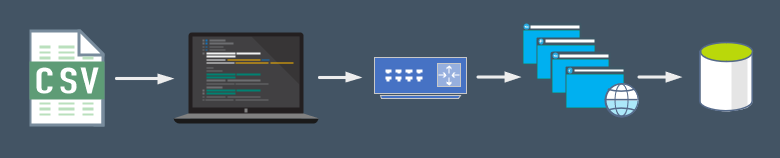
I’ve got lots of resources that I’m not using right now, because I’m only sending one request at a time, so what I want to do is start loading the data in parallel.
Let’s look at a convenient way of doing this, using the System.Threading.Tasks.Dataflow package, which is available for .NET Framework 4.5+ and .NET Core.
The Dataflow components provide various ways of doing asynchronous processing, but here I’m going to use the ActionBlock, which allows me to post messages that are subsequently processed by a Task, in a callback. More importantly, it let’s me process messages in parallel.
Let’s look at the code for my new StreamDataInParallel method:
| private static async Task StreamDataInParallel(StreamReader fileSource, HttpClient httpClient, string path, int maxParallel) | |
| { | |
| var block = new ActionBlock<string>( | |
| async json => | |
| { | |
| await httpClient.PostAsync(path, new StringContent(json, Encoding.UTF8, "application/json")); | |
| }, new ExecutionDataflowBlockOptions | |
| { | |
| // Tells the action block how many we want to run at once. | |
| MaxDegreeOfParallelism = maxParallel, | |
| // 'Buffer' the same number of lines as there are parallel requests. | |
| BoundedCapacity = maxParallel | |
| }); | |
| string line; | |
| while ((line = await fileSource.ReadLineAsync()) != null) | |
| { | |
| // This will not continue until there is space in the buffer. | |
| await block.SendAsync(GetDataJson(line)); | |
| } | |
| } |
The great thing about Dataflow is that in only about 18 lines of code, I’ve got parallel processing of data, pushing HTTP requests to a server at a rate of my choice (controlled by the maxParallel parameter).
Also, with the combination of the SendAsync method and specifying a BoundedCapacity, it means I’m only reading from my file when there are slots available in the buffer, so my memory consumption stays low.
I’ve run this a few times, increasing the number of parallel requests each time, and the results are below:
Sadly, I wasn’t able to run the benchmarking tests on the production environment (for what I hope are obvious reasons), so I’m running all this locally; the number of parallel requests I can scale to is way higher in production, but it’s all just a factor of total available cores and database server performance.
Value of maxParallel | Average Records/Second |
| 1 | 750 |
| 2 | 1293 |
| 3 | 1785 |
| 4 | 2150 |
| 5 | 2500 |
| 6 | 2777 |
| 7 | 2941 |
| 8 | 3125 |
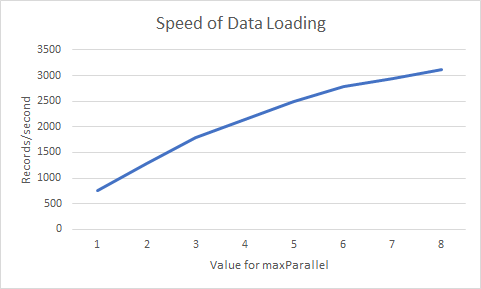
With 8 parallel requests, we get over 3000 records/second, with a time of 32 seconds to load our 100,000 records.
You’ll notice that the speed does start to plateau (or at least I get diminishing returns); this will happen when we start to hit database contention (typically the main throttling factor, depending on your workload).
I’d suggest that you choose a sensible limit for how many requests you have going so you don’t accidentally denial-of-service your environment; we’ve got to assume that there’s other stuff going on at the same time.
Anyway, in conclusion, Dataflow has got loads of applications, this is just one of them that I took advantage of for my problem. So that’s it, go forth and load data faster!
