I’m super excited today, along with the rest of the Autofac team, to be able to announce the release of Autofac 6.0!
This version has got some major new features in it, and general improvements throughout the library,
including an overhaul of the Autofac internals to use a customisable Resolve Pipeline when resolving services, built-in diagnostic support, support for the composite pattern, and more!
I’d like to thank everyone on the Autofac team for the load of effort that has gone into this release, I’m pretty thrilled to be able to unleash it into the world.
There’s a couple of breaking changes you should be aware of, and then I’ll go through an overview of some of the great new features at your disposal!
Breaking Changes
Despite the pretty big internal changes, the number of breaking changes are pretty low; we’ve managed to avoid any real behavioural changes.
You can see the complete set of breaking code changes between 5.x and 6.0 in our documentation. I’ll list some of the more pertinent ones here.
Framework Version Targeting Changes
Starting with Autofac 6.0, we now only target netstandard2.0 and netstandard2.1; we have removed the explicit target for net461.
The impact to you is that, while Autofac will still work on .NET Framework 4.6.1 as it did before, we strongly encourage you to upgrade to .NET Framework 4.7.2 or higher, as per the .NET Standard Documentation, to avoid any of the known dependency issues when using .NET Standard packages in .NET Framework 4.6.1.
Custom Registration Sources
If you have implemented a custom registration source you will need to update the IRegistrationSource.RegistrationsFor method.
// 5.x
IEnumerable<IComponentRegistration> RegistrationsFor(Service service, Func<Service, IEnumerable<IComponentRegistration>> registrationAccessor);
// 6.x
IEnumerable<IComponentRegistration> RegistrationsFor(Service service, Func<Service, IEnumerable<ServiceRegistration>> registrationAccessor);
The registrationAccessor parameter is a callback that, given a service, will return the set of registrations available for that service.
In 6.x, the return type of this callback was changed from IEnumerable to IEnumerable.
A ServiceRegistration encapsulates the registration (via the Registration property of the type), but also exposes the resolve pipeline Autofac needs in order to resolve
a registration.
Custom Constructor Selectors
If you have implemented a custom IConstructorSelector to pass to the UsingConstructor registration method, you will need to update your implementation to use BoundConstructor instead of ConstructorParameterBinding.
The new BoundConstructor type exposes similar properties (including the TargetConstructor):
// v5.x
ConstructorParameterBinding SelectConstructorBinding(ConstructorParameterBinding[] constructorBindings, IEnumerable<Parameter> parameters);
// v6.x
BoundConstructor SelectConstructorBinding(BoundConstructor[] constructorBindings, IEnumerable<Parameter> parameters);
New Features/Improvements
There are a tonne of new features in Autofac 6.0; I’ll hit some of the highlights here.
Pipelines
The internals of Autofac have been through a major overhaul, so that the work of actually resolving an instance of a registration is implemented as a pipeline, consisting of middleware that handles each part of the process.
The existing ways you configure Autofac haven’t changed, but we have added some powerful
new extensibility points you can use for advanced scenarios.
For example, you can add pipeline middleware to all resolves of a service, that runs before
any built-in Autofac code:
var builder = new ContainerBuilder();
// Run some middleware at the very start of the pipeline, before any core Autofac behaviour.
builder.RegisterServiceMiddleware<IMyService>(PipelinePhase.ResolveRequestStart, (context, next) =>
{
Console.WriteLine("Requesting Service: {0}", context.Service);
// Continue the pipeline.
next(context);
});
Anyone familiar with ASP.NET Core middleware may notice some similarities here! We have a context, and a next method to call to continue the pipeline.
You can check out our detailed docs on pipelines for a complete run down on how these work, and how to use them.
A lot of the following new features are only possible because of the pipeline change; it gave us the flexibility to do new and interesting things!
Support for the Composite Pattern
For some time we’ve been working towards adding built-in support for the Composite Pattern, going back to 2016.
Well, it’s finally here, and gives you the new RegisterComposite method on the ContainerBuilder!
Here’s an example from our documentation, where we have multiple log sinks that we want to wrap
in a CompositeLogSink:
var builder = new ContainerBuilder();
// Here are our normal implementations.
builder.RegisterType<FileLogSink>().As<ILogSink>();
builder.RegisterType<DbLogSink>().As<ILogSink>();
// We're going to register a class to act as a Composite wrapper for ILogSink
builder.RegisterComposite<CompositeLogSink, ILogSink>();
var container = builder.Build();
// This will return an instance of `CompositeLogSink`.
var logSink = container.Resolve<ILogSink>();
logSink.WriteLog("log message");
// ...
// Here's our composite class; it's just a regular class that injects a
// collection of the same service.
public class CompositeLogSink : ILogSink
{
private readonly IEnumerable<ILogSink> _implementations;
public CompositeLogSink(IEnumerable<ILogSink> implementations)
{
// implementations will contain all the 'actual' registrations.
_implementations = implementations;
}
public void WriteLog(string log)
{
foreach (var sink in _implementations)
{
sink.WriteLog(log);
}
}
}
Thanks to @johneking for his input and feedback on the design of the composites implementation.
There’s more guidance around how to use composites (including how to register open-generic composites, and use relationships like Lazy and Func) in our documentation on composites.
Diagnostic Tracing
One thing that has always been a bit challenging with Autofac (and Dependency Injection in general really), is figuring out why something isn’t working, and particularly which
one of your services in your really complex object graph is causing your problem!
Happily, in Autofac 6.0, we have added built-in support for the .NET DiagnosticSource class, and we generate diagnostic events while we are resolving a service.
The easiest way to get started with our diagnostics is using the Autofac DefaultDiagnosticTracer, which will generate a tree-like view of each resolve,
with dependencies, showing you exactly where things go wrong.
var builder = new ContainerBuilder();
// A depends on B1 and B2, but B2 is going to fail.
builder.RegisterType<A>();
builder.RegisterType<B1>();
builder.Register<B2>(ctx => throw new InvalidOperationException("No thanks."));
var container = builder.Build();
// Let's add a tracer.
var tracer = new DefaultDiagnosticTracer();
tracer.OperationCompleted += (sender, args) =>
{
// TraceContent contains the output.
Trace.WriteLine(args.TraceContent);
};
container.SubscribeToDiagnostics(tracer);
// Resolve A - will fail.
container.Resolve<A>();
When that Resolve<A>() call completes, our tracer’s event handler will fire, and TraceContent contains your verbose trace:
Resolve Operation Starting
{
Resolve Request Starting
{
Service: AutofacDotGraph.A
Component: AutofacDotGraph.A
Pipeline:
-> CircularDependencyDetectorMiddleware
-> ScopeSelectionMiddleware
-> SharingMiddleware
-> RegistrationPipelineInvokeMiddleware
-> ActivatorErrorHandlingMiddleware
-> DisposalTrackingMiddleware
-> A (ReflectionActivator)
Resolve Request Starting
{
Service: AutofacDotGraph.B1
Component: AutofacDotGraph.B1
Pipeline:
-> CircularDependencyDetectorMiddleware
-> ScopeSelectionMiddleware
-> SharingMiddleware
-> RegistrationPipelineInvokeMiddleware
-> ActivatorErrorHandlingMiddleware
-> DisposalTrackingMiddleware
-> B1 (ReflectionActivator)
<- B1 (ReflectionActivator)
<- DisposalTrackingMiddleware
<- ActivatorErrorHandlingMiddleware
<- RegistrationPipelineInvokeMiddleware
<- SharingMiddleware
<- ScopeSelectionMiddleware
<- CircularDependencyDetectorMiddleware
}
Resolve Request Succeeded; result instance was AutofacDotGraph.B1
Resolve Request Starting
{
Service: AutofacDotGraph.B2
Component: λ:AutofacDotGraph.B2
Pipeline:
-> CircularDependencyDetectorMiddleware
-> ScopeSelectionMiddleware
-> SharingMiddleware
-> RegistrationPipelineInvokeMiddleware
-> ActivatorErrorHandlingMiddleware
-> DisposalTrackingMiddleware
-> λ:AutofacDotGraph.B2
X- λ:AutofacDotGraph.B2
X- DisposalTrackingMiddleware
X- ActivatorErrorHandlingMiddleware
X- RegistrationPipelineInvokeMiddleware
X- SharingMiddleware
X- ScopeSelectionMiddleware
X- CircularDependencyDetectorMiddleware
}
Resolve Request FAILED
System.InvalidOperationException: No thanks.
at AutofacExamples.<>c.<ErrorExample>b__0_0(IComponentContext ctx) in D:\Experiments\Autofac\Examples.cs:line 24
at Autofac.RegistrationExtensions.<>c__DisplayClass39_0`1.<Register>b__0(IComponentContext c, IEnumerable`1 p)
at Autofac.Builder.RegistrationBuilder.<>c__DisplayClass0_0`1.<ForDelegate>b__0(IComponentContext c, IEnumerable`1 p)
at Autofac.Core.Activators.Delegate.DelegateActivator.ActivateInstance(IComponentContext context, IEnumerable`1 parameters)
...
X- A (ReflectionActivator)
X- DisposalTrackingMiddleware
X- ActivatorErrorHandlingMiddleware
X- RegistrationPipelineInvokeMiddleware
X- SharingMiddleware
X- ScopeSelectionMiddleware
X- CircularDependencyDetectorMiddleware
}
Resolve Request FAILED: Nested Resolve Failed
}
Operation FAILED
There’s a lot there, but you can see the start and end of the request for each of the child dependencies, including content telling you exactly which registration failed and every pipeline middleware visited during the operation.
We’re hoping this will help people investigate problems in their container, and make it easier to support you!
We’ve got some detailed documentation on diagnostics, including how to set up your own
tracers, go check it out for more info.
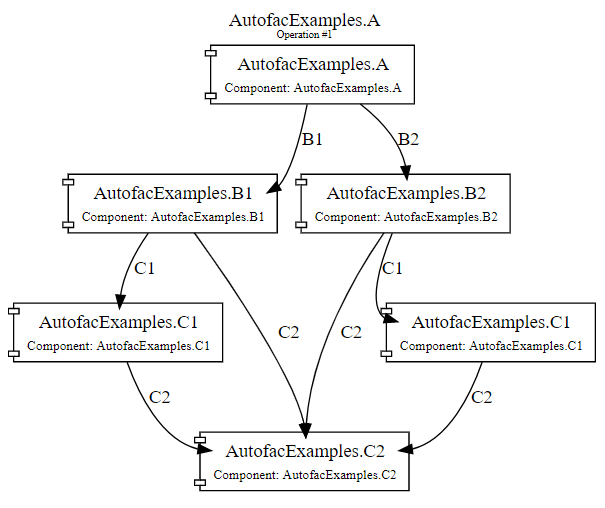
Visualising your Services
Building on top of the diagnostics support I just mentioned, we’ve also added support for outputting graphs (in DOT format) representing your resolve operation, which can then be rendered to an image, using the Graphviz tools (or anything that can render the DOT format).
This feature is available in the new NuGet package, Autofac.Diagnostics.DotGraph.
var builder = new ContainerBuilder();
// Here's my complicated(ish) dependency graph.
builder.RegisterType<A>();
builder.RegisterType<B1>();
builder.RegisterType<B2>();
builder.RegisterType<C1>();
builder.RegisterType<C2>().SingleInstance();
var container = builder.Build();
// Using the new DOT tracer here.
var tracer = new DotDiagnosticTracer();
tracer.OperationCompleted += (sender, args) =>
{
// Writing to file in-line may not be ideal, this is just an example.
File.WriteAllText("graphContent.dot", args.TraceContent);
};
container.SubscribeToDiagnostics(tracer);
container.Resolve<A>();
Once I convert this to a visual graph (there’s a useful VSCode Extension that will quickly preview the graph for you), I get this:
If you’ve got a big dependency graph, hopefully this will help you understand the chain of dependencies more readily!
There’s more information on the DOT Graph support in our documentation.
Pooled Instances
A new Autofac package, Autofac.Pooling, is now available that provides the functionality to maintain a pool of object instances within your Autofac container.
The idea is that, for certain resources (like connections to external components), rather than get a new instance for every lifetime scope, which is disposed at the end of the scope, you can retrieve from a container-shared pool of these objects, and return to the pool at the end of the scope.
You can do this by configuring a registration with PooledInstancePerLifetimeScope or PooledInstancePerMatchingLifetimeScope methods:
var builder = new ContainerBuilder();
// Configure my pooled registration.
builder.RegisterType<MyCustomConnection>()
.As<ICustomConnection>()
.PooledInstancePerLifetimeScope();
var container = builder.Build();
using (var scope = container.BeginLifetimeScope())
{
// Creates a new instance of MyCustomConnection
var instance = scope.Resolve<ICustomConnection>();
instance.DoSomething();
}
// When the scope ends, the instance of MyCustomConnection
// is returned to the pool, rather than being disposed.
using (var scope2 = container.BeginLifetimeScope())
{
// Does **not** create a new instance, but instead gets the
// previous instance from the pool.
var instance = scope.Resolve<ICustomConnection>();
instance.DoSomething();
}
// Instance gets returned back to the pool again at the
// end of the lifetime scope.
You can resolve these pooled services like any normal service, but you’ll
be getting an instance from the pool when you do!
Check out the documentation on pooled instances for details on how to control
pool capacity, implement custom behaviour when instances are retrieved/returned to
the pool, and even how to implement custom pool policies to do interesting things like throttle your application based on the capacity of the pool!
Generic Delegate Registrations
Autofac has had the concept of open generic registrations for some time, where you can specify an open-generic type to provide an open-generic service.
var builder = new ContainerBuilder();
// Register a generic that will provide closed types of IService<>
builder.RegisterGeneric(typeof(Implementation<>)).As(typeof(IService<>));
In Autofac 6.0, we’ve added the ability to register a delegate to provide the generic, instead of a type, for advanced scenarios where you need to make custom decisions about the resulting closed type.
var builder = new ContainerBuilder();
builder.RegisterGeneric((ctxt, types, parameters) =>
{
// Make decisions about what closed type to use.
if (types.Contains(typeof(string)))
{
return new StringSpecializedImplementation();
}
return Activator.CreateInstance(typeof(GeneralImplementation<>).MakeGenericType(types));
}).As(typeof(IService<>));
Concurrency Performance Improvements
There’s been a lot of work into performance with this release of Autofac; particularly around performance in highly-concurrent scenarios, like web servers.
We’ve removed a load of locking from the core of Autofac, to the point that once a service has been resolved once from a lifetime scope, subsequent resolves of that service are lock-free.
In some highly-concurrent scenarios, we’ve seen a 4x reduction in the time it takes to resolve objects through Autofac!
Thanks @alsami for the work on automating our benchmark execution, @twsouthwick for work on caching generated delegate types, and @DamirAinullin for varied performance tweaks.
Other Changes
- Support async handlers for OnPreparing, OnActivating, OnActivated and OnRelease (PR#1172).
- Circular Dependency depth changes to allow extremely deep dependency graphs that have no circular references (PR#1148).
ContainerBuilder is now sealed (Issue#1120).- Explicitly injected properties can now be declared using an expression (PR#1123, thanks @mashbrno).
Still Todo
We’re working hard to get all of the ~25 integration packages pushed to NuGet as quickly as
we can, so please bear with us while we get these sorted.
Some of this is sitting in branches ready to go, other things need to be done now that we have this core package out there.
If your favorite integration isn’t ready yet, we’re doing our best. Rather than filing "When will this be ready?" issues, consider pull requests with the required updates.
Thank You!
I’d like to personally thank all the contributors who contributed to the 6.0 release since we shipped 5.0:
Hopefully the Github Contributors page hasn’t let me down, I wouldn’t want to miss anyone!